데이터프레임은 2차원 배열의 형태를 띄고있다.
데이터프레임은 파이썬은 딕셔너리로 생각해도 좋다.
데이터프레임을 구축하는 요소로 시리즈가 있다.
키:시리즈
키:시리즈
데이터 프레임은 위의 형태로 시리즈를 내포하고있다. (딕셔너리)
이때 데이터 프레임은 행,열 의 구조가되며 각 열은 시리즈(리스트)를 갖고있으며
행은 키들로 구분된다.
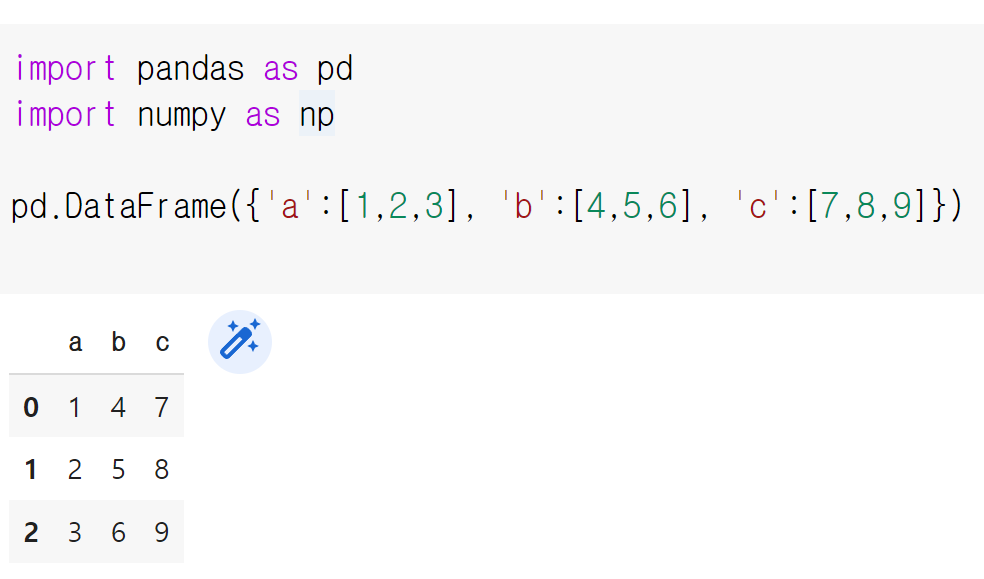
실제로 DataFrame()이 입력받는 인자가 딕셔너리이다.
각 키들은 columns, 값들은 rows가 된다.
그리고 왼쪽은 0,1,2는 인덱스를 뜻한다.

데이터프레임을 생성할 때 위와 같이 index와 columns의 이름을 정해줄 수도 있다.
그런데 이때 주의할 점이 DataFrame에 들어가는 숫자형 데이터는 2중 리스트라는 것이다.
그럼 이제 데이터프레임의 사용법에 대해 알아보겠다.
index, columns

데이터 프레임을 index와 columns를 추출한다.
set_index()와
set_columns()가 가능하다.
열 선택

데이터 프레임에서 column을 부름으로써 모든 행에 대한 column의 값(시리즈)을 가져올 수 있다.
행 선택 (loc)

행을 선택하고 해당 행에 포함된 모든 열의 값을 추출한다.
이때 같은 방식으로 slicing도 가능하다.
slicing



특이한 점으로 슬라이싱은 loc를 사용하지 않아도 인덱스를 기준으로 한다.
특정행 특정열 선택

특정 행, 특정 열을 선택하고 싶을 때 위와 같이 사용할 수 있다.
행 선택 (iloc)

결과는 loc와 동일하지만 숫자를 해용해 인덱스를 참조한다.
iloc로도 특정 열, 행 선택을 할 수 있다.

부울인덱싱(boolean)

새로운 column 추가 및 Nan 활용

새로운 column을 추가할 수도 있고 값을 nan으로 지정할 수도 있다.
이때 삭제는 del을사용한다.
del my_dataFrame['new_column'] or my_dataFrame.dropna()
하지만 nan값을 삭제하지 않고 다른 값으로 채워 넣을 수도 있다.
누락데이터 채우기

이와 같이 누락된 데이터에 직접 값을 지정해서 채울 수도 있다.
또는 메소드를 이용할 수도 있다.
- ffill : 누락 데이터를 위의 데이터로 채운다.
- bfill : 누락 데이터를 아래의 데이터로 채운다.

해당 예제에서
ffill을 사용하면 첫번째 Nan의 위의 데이터 3.0으로 Nan을 채우고
다음 Nan은 또 해당 Nan의 위쪽 데이터로 Nan을 채우게 된다.
bfill을 사용하면 첫번째 Nan의 아래의 데이터로 Nan을 채우게 되는데
아래의 데이터도 Nan이라 결과적으로 Nan은 바뀌지 않고
두번때 Nan또한 아래의 데이터가 존재하지 않기에 Nan이 바뀌지 않았다.
상황에 따라 ffill, bfill을 적절히 사용해야 한다.
'Python > Pandas' 카테고리의 다른 글
| [Pandas] 시리즈 2 (Series) (0) | 2022.05.01 |
|---|---|
| [Pandas] 시리즈 (Series) (0) | 2022.04.30 |
| [Pandas] 판다스 입문 (1) | 2022.04.30 |